
I found a tool that sounds like it would be suited to a project comparing a novel and its screenplay adaptation (it is, of course, far more complicated than this assignment allows). The tool is called PAIR: Pairwise Alignment for Intertextual Relations. From its site:
PAIR (Pairwise Alignment for Intertextual Relations) is a simple implementation of a sequence alignment algorithm for humanities text analysis designed to identify “similar passages” in large collections of texts. These may include direct quotations, plagiarism and other forms of borrowings, commonplace expressions and the like.
In playing with Juxta, I compared the opening scene of the film with the passage in the novel. While it didn’t provide any great insights, it was useful to have both side-by-side:
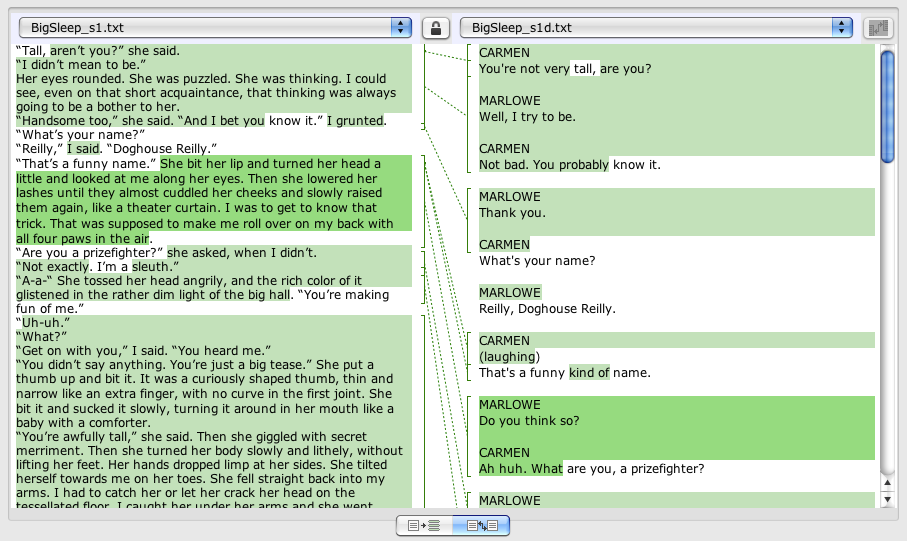
The areas that are NOT highlighted in green are exact matches. You can see that dialogue that is almost the same doesn’t necessarily stand out in this system.
Since this project got rather complicated quickly, I also did some playing with Voyant and Google N-Grams.

In Voyant, I visualized the entire text of the novel and used the standard Taporware (English) stopwords. Two words stood out to me: “said,” which I suppose indicates that the book is heavy on dialogue, and “door,” which I find interesting.
Changing topics briefly, I used Google N-Grams to look at the change in usage of terms in film studies. I chose “photoplay,” “moving picture,” “motion picture,” and “cinema,” for the period 1900-1980.
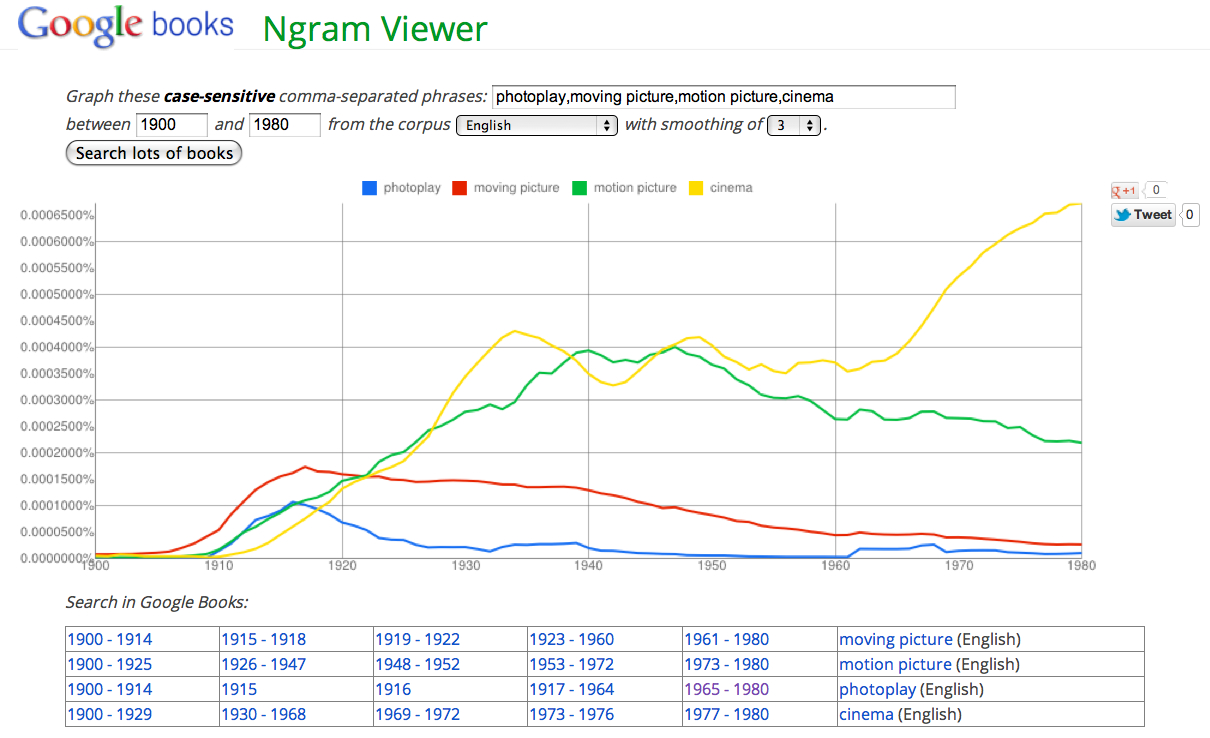 It’s pretty clear that the early 1920s saw a switch from “moving picture” to “motion picture.” I can see how a tool like this would help me narrow down a period of study in researching this change. Also, “moving picture” and “photoplay” seem to peak around 1915, which I know from my previous research is also the first appearance of “moving pictures” in the Library of Congress Classification system. This made me want to revisit the topic and compare the evolution of the LCC schedules with the Google Books corpus.
It’s pretty clear that the early 1920s saw a switch from “moving picture” to “motion picture.” I can see how a tool like this would help me narrow down a period of study in researching this change. Also, “moving picture” and “photoplay” seem to peak around 1915, which I know from my previous research is also the first appearance of “moving pictures” in the Library of Congress Classification system. This made me want to revisit the topic and compare the evolution of the LCC schedules with the Google Books corpus.
I had fun playing with the different tools, but it can be a bit overwhelming trying to make sense of the specialized vocabulary and the long list of tools available. I can definitely see a role here for a reference librarian in consulting with students and researchers, to help recommend some tools to start with.
Roxanne I thought this post was excellent in providing context on how an idea was converted depending on the tool you were exploring. You always provide us with great commentary!!
I must admit I had trouble navigating some of the tools even after watching the help video. This post was a great way of helping me gain an understanding of how the tool could be used and for displaying the type of outcome I might receive had I been able to achieve success. I thought my experience with Voyant would be more interesting than it turned out. I entered a series of words, tried to find a corpus that applied and then I tried the reverse but I got nothing. It interests me that in your exploration the most popular word was “said,” which allowed you to make this connection to the heavy use of dialogue. The value of indicators and drawing conclusions proves to be great for building a path to research.
A couple of weeks back I played with Ngram viewer and this was a tool I enjoyed. There is something about all the visual representation that I respond to which may or may not be superficial. This tool was also interesting to me since it responded well to my converting back and forth between Spanish language and English language corpus. In my case I compared books by Latin American authors from 1965 – early 2000’s. Isabel Allende – “Eva Luna”, Paolo Coelho “The Alchemist”, Mario Vargas Llosa “The Storyteller” and Gabriel Garcia Marquez “In Evil Hour”.
Thanks for this and your previous process-related post, Roxanne! It’s really excellent to see you playing with these tools.
I agree that it would be helpful to have some guidance on these tools, and I regret that I’m not able to provide more of it. I’m going to see whether I can draw in some DH colleagues to help.
Having said that, it would be worth checking out DH Questions and Answers (http://digitalhumanities.org/answers/) for additional guidance.