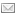IMO Voyant Tools helps one tear into the text. Yes, it has appealing graphics: both visual representation and color, which made me wonder if there was some meaning imbedded there, which I was neither aware of nor able to figure out. However, once one peels those layers and looks for functionality, there’s no disappointment. I entered a short text from a letter from Virginia Woolf to Dora Carrington after the death of Lytton Strachey:
“Oh but Carrington we have to live and be ourselves—and I feel it is more for you to live than for any one; because he loved you so, and loved your oddities and the way you have of being yourself. I cant explain it; but it seems to me that as long as you are there, something we loved in Lytton, something of the best part of his life still goes on. But goodness knows, blind as I am, I know all day long, whatever I’m doing, what you’re suffering. And no one can help you.”
There is 1 document in this corpus with a total of 97 words and 66 unique words.
Most frequent words in the corpus: and (5), you (5), i (4), as (3), but (3).
The above is a statistical sum-up of the text, which shows the literary skills of Woolf even in letters (more than 2/3 are words that don’t repeat, which to me is a high vocabulary density). The text is strategically placed in the middle and the little box below lets you choose the word you want to trace in the text and it highlights only that word and all the instances it appears in. That is a very useful tool for anyone, especially someone who writes. It makes one more aware of the choice of words or preferences for certain words. I can see this tool as a way to teach students why it’s important not to repeat content words too much and what words would be acceptable to appear a number of times in the text. This would go well with vocabulary work (Thesaurus). Rather than have them look up words, this would create the immediacy that is necessary to help people become proactive. It allows them to see that there is a problem that needs to be addressed. The graph on the right looks enticing. I still haven’t figured out how to use it, even though I know that you can add a number of words and look at their frequency and interconnectedness in the context. The best feature is that there is a pre-recorded tutorial that explains how to use the tools and it’s a lot more sophisticated than for what I used it. This could be a perfect tool for a dissertation: both working with literary works or student data, especially if you have to come up with categories. You can look up certain words and scan the text for their frequency. The question remains how to use it more efficiently.